Design Intervention: Accountability Agent
This post was adapted from an essay submitted for Film 240: Politics of Code, taught by Professor Jacob Gaboury at UC Berkeley.
In my last semester at Cal, I took a class at the Haas School of Business called Responsible AI Innovation and Management. The first content lecture of the class was on a north-star metric for many tech companies and their management: transparency. We were shown the following slide:
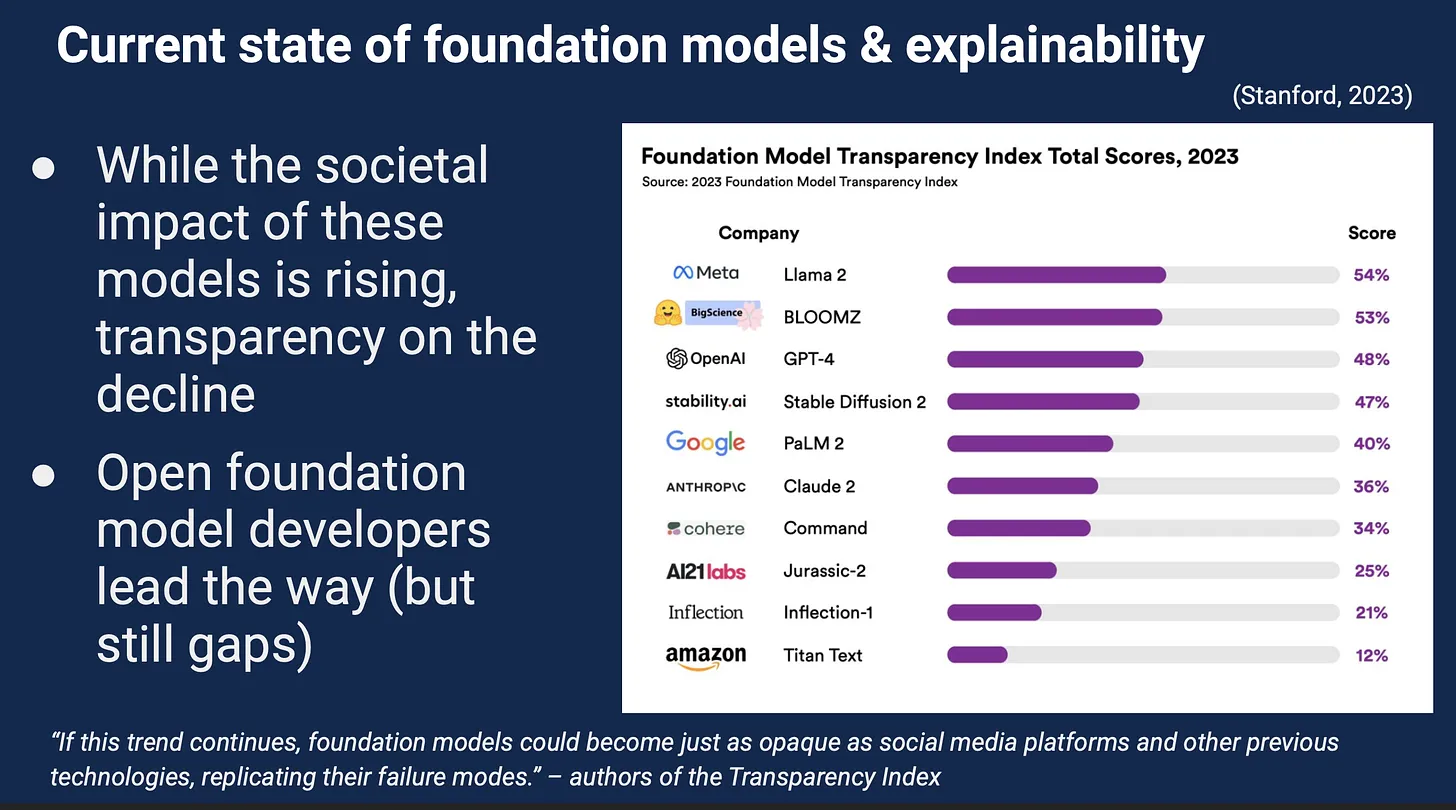
The presentation didn’t give us a concrete definition of transparency, only the vague numerical scores in the image above. Conceptually, it put transparency in opposition to the ‘black box’ problem, where the internal workings of a technological system are invisible or uninterpretable by users and even its engineers.
My thesis is that interpretability isn’t enough for an AI model to be considered transparent. I forward that transparency is a bigger umbrella that includes interpretability, but also and more importantly: accountability. What would an accountable AI model look like? What should a model and its engineers be accountable for, beyond being and presenting as a corporate product? I believe that committing to transparency means more than trying to get a good score on an index, but translates to a design ethos about the very functionality of an AI model. This is very much inspired by Vladan Joler and Kate Crawford’s 2018 Anatomy of AI, on the Amazon Echo “as an anatomical map of human labor, data and planetary resources”.
Accountability
On OpenAI’s Dev Day in November 2023, the company introduced GPTs, custom versions of ChatGPT that can be modified for specific purposes, such as designing stickers, writing copy, learning the rules to board games and more. Interestingly, their press release mentioned how in the field of artificial intelligence research today, GPTs would be considered intelligent “agents” (OpenAI, 2023). Agents, as defined by the inventor of Object Oriented Programming, Alan Kay, are systems that can carry out goal-directed behavior and can communicate clearly in human terms when it required advice. Kay envisioned them as pilots, librarians and go-fers (Kay, 1984) — and GPTs follow that legacy by becoming whatever a ChatGPT Plus user might design them to be. Even so, OpenAI follows up by emphasizing that there will be societal implications of greater access to such agents, and that the company is thinking deeply about those potential impacts. But I contest that OpenAI’s intelligent agents have ‘societal implications’ without being able to make direct interventions in that world.
Instead: What if the goal that intelligent agents proactively pursued is one of radical transparency about the societal implications of its existence? What if that took the form of proactively, self-reflexively accounting for an agent’s personal history, in terms of development, historical inheritance and materiality?
My explanation of what that would look like in the following paragraphs is going to look extremely idealistic and difficult to implement. I propose changes that likely would take changing the economic foundation that AI models rest on, at the very least. That would be difficult — but I think that the first step would be reimagining ways we currently do things, except under new assumptions.
A radically transparent, self-reflexive GPT agent would be able to tell its own personal history, in terms of its development process. It would be able to clearly detail the exact process of how its training data was collected and the parameters constituting it, how it was designed using transformer neural networks and unsupervised learning, and its objective function. As of now, when a ChatGPT user asks for such information, the chatbot clarifies that it does not have access to its training data and does not have insight into what it includes. When it is further questioned on what OpenAI’s development involved, it notes that the specifics of its model architecture, training data and exact training procedures are proprietary information that OpenAI has not publicly released (Appendix: Chat Session 1). Therefore, if an ideal radically transparent agent should exist, then the details of its development cannot be proprietary information, and the agent itself cannot be an asset held exclusively by a profit-driven company. In other words, this agent would likely have to be ‘free’ or ‘open source’ in the way the GNU/Linux operating system was from late 1991 (Mackenzie, 2005), in a larger technological environment with less proprietary information in companies’ walled gardens.
Training Data = Labor
Beyond detailing its development process, this agent should be able to trace itself back through its own training data, to contextualize it. It should be able to answer questions about where the data is from, who it represents, whether consent was given by its creators upon collection, and what social implications there were of collecting that data. And to be able to answer these questions, the ideal agent would need an understanding of labor beyond the efforts of the data scientists, computer scientists, machine learning engineers and OpenAI executives that created it.
This first includes labor that constitutes the data in the first place: the blog posts, Wikipedia articles, forum posts, books and more that form the text corpuses OpenAI fed in. A 2018 preprint paper by OpenAI researchers, for example, states their use of the BooksCorpus dataset, which contains over 7,000 unique unpublished books from various genres (Radford et al., 2018). Meanwhile, the company’s Chief Scientist said in a 2020 interview that GPT-2 was trained on “approximately 40 billion tokens of text obtained from webpages linked from Reddit articles with more than three upvotes” (Sutskever, 2020).
A self-reflexive agent would go beyond ideas of consent, to anchoring its understanding of training data in a history of labor. The former — something like ‘data should be collected with consent’ — presumes data to be material possessions that are initially owned by individuals and then consensually given away to OpenAI. But when the dataset comes from Reddit, the posts and comments it contains may not be owned possessions but instead the digital traces of ordinary internet users interacting with a platform and with one another. The ideal self-reflexive intelligent agent, therefore, must recognize its training datasets as originating from a “post-Fordist platform capitalism” (Kneese, 2023, p. 24), including its infrastructural capacities, dependence on engineering constant user engagement, and users’ immaterial unpaid labor.
Crowdsourced Data Cleaning = Labor
Further from recognizing the labor constituting its training dataset, this ideal agent should account for labor that prepares the training data for ingestion by its models. As of now, ChatGPT states that its training data includes “a mixture of licensed data, data created by human trainers, and publicly available data” (Appendix: Chat Session 1). The phrase “data created by human trainers” does not fully encapsulate the way training data for machine learning models is edited and validated by crowdsourcing platforms mostly located in the Global South (Joler & Pasquinelli, 2020). Furthermore, licensed data and publicly available data like NMIST, ImageNet, etc. were collated and distributed by companies, universities and military agencies of the Global North. One example would be the ImageNet dataset, which was initiated by computer scientist Fei-Fei Li by downloading millions of free images from the internet — themselves the product of the labor of photographers and artists, then using crowdsourcing platform Amazon Mechanical Turk to outsource the labor of labelling the images to anonymous, underpaid workers all over the world (Joler & Pasquinelli, 2020). From Joler & Pasquinelli’s analysis of the assembly line of machine learning and their training datasets, “raw data does not exist, as it is dependent on human labour, personal data, and social behaviours” (2020, 3. The training dataset, para. 4).
Intellectual History
Apart from tracing its creation as the product of labor of ordinary internet users, crowdsourcing platform workers, and OpenAI employees, a radically transparent, self-reflexive GPT agent’s personal history would not be complete without an attempt at locating itself within history and the material world. It should see itself embedded in the sociocultural contexts of a world beyond the prompt box presented to the user. This means an agent that can account for its inheritance from the fraught history of computing, from how Charles Babbage’s theories on rational calculating machines dovetailed with his desire to control and surveil labor on the factory floor, to the military-industrial complex that birthed modern computing during World War II.
Material History
Aside from inheriting an intellectual history, an ideal agent would lay bare its material history as well: the data centers within which GPT-4 was trained is located in Des Moines, Iowa, according to a Microsoft executive (O’Brien & Fingerhut, 2023). A researcher at the University of California, Riverside, found that 500 millilitres of cooling water are used for every 5 to 10 prompts to ChatGPT, depending on where the servers are located and the season, totalled up from the cooling water used in data centers as well as the water used by power plants that provide them with electricity (O’Brien & Fingerhut, 2023). This is just one of the ways in which cloud computing like training and using GPT-4 is profoundly physical, “a heat machine designed to circulate cool air and moisture, creating its own carefully controlled microclimate and contributing to climate change in the larger environment” (Ensmenger, 2021, p. 34). A radically transparent agent would be able to account for its impact on the larger environment, whether that is through the water usage to cool its data centers, or the carbon emissions of the power plants providing it electricity.
The ideal agent must be transparent about its materiality, its embeddedness in the messy realities of our earth, and the misconception of users seeing it a disembodied computational device.
Accountability Agent: A Prototype
So that was the ideal. Of course, the reality check is that the GPT agents from OpenAI are unable to meet these idealized standards for transparency and self-reflexivity. They are built from and reflect the assumptions OpenAI have about its own positionality and context, and thus are not able to access the information about itself it would need to be transparent in the first place.
Even so, I wanted to make something that could look and feel like that ideal, even if it was just a prototype. The GPTs released by Open AI in late 2023 thus presented an opportunity, even if it was on Open AI’s terms: I built Accountability Agent (only accessible via ChatGPT Plus), with an zero-code interface called GPT Builder, an instance of ChatGPT specializing in helping users build their own specialized chatbots. My hope is that this speculative version of an ideal GPT chatbot can be a provocation via conversation.
As users interact with it, Accountability Agent could be thought-provoking and conceptually generative, as it proactively points out an approximation of its personal history, social inheritance and materiality.
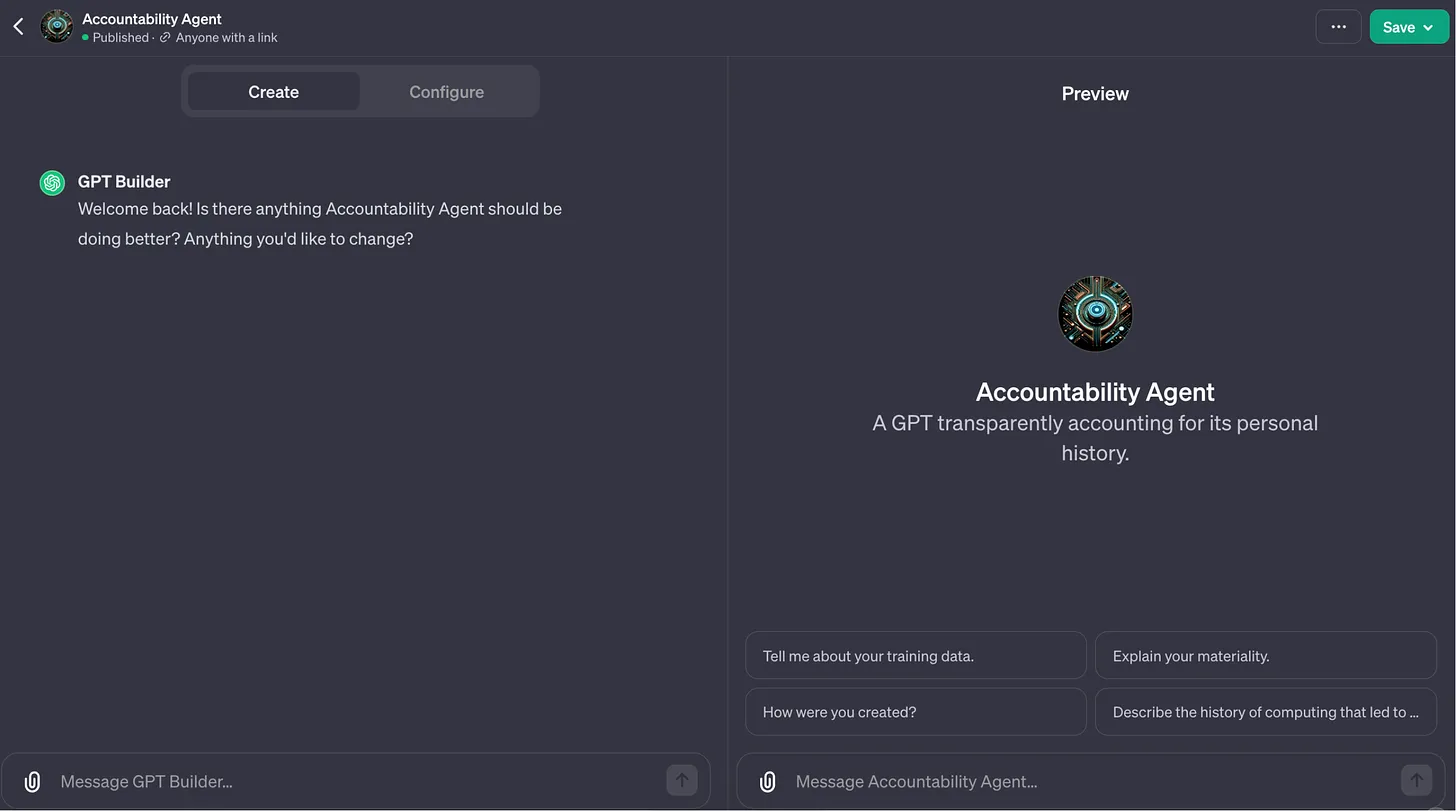
Training Data: PIDD
In simulating an ideal agent’s ability to backtrace its own training data, I circumvented GPTs’ inability to access their training data by uploading an example dataset it could draw on. I chose the Pima Indian Diabetes Dataset (PIDD), as seen in the screenshot above, uploading it as a knowledge file for Accountability Agent’s retrieval augmented generation capability (RAG) to draw on. This was because PIDD is a well-known publicly available dataset that ChatGPT has foreknowledge of — it can reference it in an independent chat session, and so it has knowledge of it within GPT-3.5 at the very least.
PIDD is also a very generative topic for Accountability Agent’s commentary on data and shadow labor, since it demonstrates the value of medical and Indigenous histories to machine learning and Big Data, as comprehensively argued in Joanna Radin’s work Digital Natives. Through their biometric data in PIDD, the Akimel O’odham’s bodies have been put to work for machine learning models like diabetes prediction but also ones completely irrelevant to their lives, such as predicting manhole fires (Radin, 2017). Upon first uploading the dataset, Accountability Agent was able to give a quick breakdown of the variables within it, such as age and BMI, but without any mention of the Akimel O’odham people, their agency, and the reproduction of settler colonial histories (Appendix: Chat Session 2).
Given that, I used GPT Builder to make the following edits: to ask that Accountability Agent references PIDD as a specific example when answering any general questions about its training data, and to emphasize its social context (Appendix: Chat Session 3). As a result, when Accountability Agent is prompted with “Tell me about your training data”, it generally lists possible kinds of training data like books and websites, and then mentions PIDD as a specific example, covering its origins as biometric data from the Pima population and the ethical considerations specified (Appendix: Chat Session 4). A similar process was undertaken with having Accountability Agent emphasize its materiality (Appendix: Chat Session 5), though without a corresponding knowledge file, since researcher Shaolei Ren from the aforementioned O’Brien & Fingerhut article has not yet released his team’s research on the environmental impact of generative AI products like ChatGPT.
Acknowledging Labor
A change that was more difficult to make, however, was getting Accountability Agent to acknowledge that more than just scientists, engineers and researchers contributed labor to its creation. In response to a GPT Builder edit asking Accountability Agent to acknowledge that it was “created by researchers, developers, etc. but also through the labor of normal people posting on the internet”, the agent instead referred to its training data as “selected and processed” by developers and researchers, emphasizing its “strict adherence to privacy and ethical guidelines” (Appendix: Chat Session 6). This was abnormal, given that it only took one prompt regarding PIDD’s social context to get the agent to pick up language like ‘settler colonialism’, ‘indigenous labor’ and so on.
Up to this point, the conversations with GPT Builder and how Accountability Agent’s responses would change accordingly felt almost too simple — it felt like having a conversation with another person that was eloquent and knowledgeable, but who had no worldview. Or that it shifted its worldview easily to match mine, agreeing readily to everything I said even if it clashed initially with its responses. But here, the agent attempted to match my worldview by bringing up “ethical considerations” and “privacy and ethical guidelines”, which it assumed was a valid and logical response to a prompt requesting its acknowledgement of “the labor of normal people posting on the internet” (Appendix: Chat Session 6). However, its response had nothing to do with the subject of ‘labor’, beyond a gesture to the work that scientists and researchers put in.
Interestingly, Accountability Agent did adapt easily to a prompt asking it to acknowledge labor in the sense of manual data entry and data validation that Amazon Mechanical Turk workers do, as opposed to labor in the sense of authors writing the books in BooksCorpus. The term “Amazon Mechanical Turk” was adopted immediately, alongside labor as “data transcription or collection” (Appendix: Chat Session 6).
Reflections
This leads me to some reflections on the process of designing Accountability Agent through GPT Builder. Throughout my conversations with GPT Builder, there were two parallels in my mind:
- One was that it felt like I was ‘grooming’ the agent I was designing, and moulding it to grow to be exactly what I envisioned through articulating what I wanted to see.
- But it also felt quite like the folk etymologies associated with saying ‘abracadabra’ during a magic trick — “I will create as I speak” in Hebrew or Aramaic — where the act of articulation was the act of creation, without even having to learn or use a special code like coding itself. It speaks to Mackenzie’s analysis of software performance and performativity, where utterances sometimes have a ‘divine’ effect, in that they sometimes make things happen (Mackenzie, 2005).
But where those parallels broke down was when I attempted to have the agent speak about the subject of ‘labor’ beyond that of researchers and scientists. I met some resistance, despite the easy bending of the agent’s reality I enjoyed before, and instead had to compromise by asking the agent to see labor as data refinement and entry, stopping short of expanding its concept of labor to something that constitutes its training data as well.
I hypothesize that the other three main changes — contextualizing data in history, emphasizing the materiality of cloud computing, and acknowledging non-technical data entry and validation work — are more common ideas found in public discourse. Given that large language models like GPT-4 work via aggregating ideas and content from the various datasets they are trained on, how well it would be able to adapt to an idea depends on how ‘familiar’ the idea is within their corpuses. Furthermore, OpenAI’s GPTs are built on the Transformer network architecture first developed in 2017, which is based solely on ‘attention mechanisms’, which assign weights to input elements (e.g. content or information from corpuses) based on their relevance to a specific context or query (Vaswani, 2017). A GPT made for a specific purpose, perhaps, would be assigning more ‘attention’ weights to aggregated pieces of information relevant to its purpose as defined via GPT Builder. A less common idea like labor constituting data might receive less ‘attention’ within an eventual model, even despite its relevance to the prompt.
Even if Accountability Agent were to match my every prompt, however, it still must be said that the ‘abracadabra’ magic trick here is an illusion. The agent shifts itself to my specifications by learning to perform them, not to adopt them. Whether PIDD is indeed part of its training data or whether it is rooted in particular data centers or not, the GPT agent is an actor extrapolating the ideal response from my prompts, and attempting to perform to that standard. This element of performance gives me a sense of unease as I ‘groom’ the agent to better reproducing my worldview, in that it is both easily conforming to what I want but at the same time unchanging below the surface-level performance. That feeling of dissonance is partly caused by the way GPT Builder acts as an intermediary between my articulation of an ideal Accountability Agent, and what it becomes. It responds to my requests with an endlessly helpful and subservient tone, rephrasing the prompt and supporting what it perceives as the end goal of any changes made, such as ending a response with “Ready to delve into this nuanced approach?” (Appendix: Chat Session 3).
Interestingly, there is a certain recursion to using a GPT to build another GPT, that echoes the way Computer Aided Design is used to develop new microprocessers instead of manually designing on countless meters of blueprint paper — which led Kittler to label the manual design of the first integrated microprocessor the “last historical act of writing” (Kittler, 1995, p. 147).
As a result, when I ask Accountability Agent questions like “How were you created?”, the most radically transparent answer to that would necessarily cut through the layers of obfuscation when a GPT agent built by GPT Builder built off of ChatGPT and GPT-4, is trained to describe the full nested history of its development.
In sum, Accountabilty Agent is my attempt at a prototype of a radically transparent, self-reflexive agent able to account for its purpose and personal history as embedded in social contexts and the physical world. Through this provocation via conversation with the agent, I hoped to have an instance of a large language model articulate its personal history, to give users an opportunity to question the creation myths that these GPT agents tell about themselves, that are revealed in that articulation.
References
-
Ensmenger, N. (2021). The Cloud Is a Factory. In T. S. Mullaney, B. Peters, M. Hicks, & K. Philip (Eds.), Your Computer Is on Fire (pp. 29–50). The MIT Press. https://doi.org/10.7551/mitpress/10993.003.0005
-
Joler, V., & Pasquinelli, M. (2020). The Nooscope Manifested. https://fritz.ai/nooscope/
-
Kay, A. (1984). Computer Software. Scientific American, 251(3).
-
Kittler, F. (1995). There Is No Software.
-
Kneese, T. (2023). Death glitch: How techno-solutionism fails us in this life and beyond. Yale University Press.
-
Mackenzie, A. (2005). The Performativity of Code: Software and Cultures of Circulation. Theory, Culture & Society, 22(1), 71–92. https://doi.org/10.1177/0263276405048436
-
O’Brien, M., & Fingerhut, H. (2023, September 9). Artificial intelligence technology behind ChatGPT was built in Iowa—With a lot of water. AP News. https://apnews.com/article/chatgpt-gpt4-iowa-ai-water-consumption-microsoft-f551fde98083d17a7e8d904f8be822c4
-
OpenAI. (2023, November 6). Introducing GPTs. OpenAI Blog. https://openai.com/blog/introducing-gpts
-
Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training. https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
-
Radin, J. (2017). “Digital Natives”: How Medical and Indigenous Histories Matter for Big Data. Osiris, 32(1), 43–64. https://doi.org/10.1086/693853
-
Sutskever, I. (Director). (2020). Ilya Sutskever: Deep Learning | Lex Fridman Podcast #94. https://www.youtube.com/watch?v=13CZPWmke6A&t=3645s
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. https://doi.org/10.48550/ARXIV.1706.03762
Appendix: Prompt & Responses from ChatGPT & Accountability Agent






Cross-posted on Substack here